计算机与信息工程学院宿通通博士在深度学习模型知识蒸馏压缩的研究中取得重要进展,提出一种全新的自蒸馏模型压缩策略以提升深度学习模型的泛化能力和鲁棒性。相关成果以“SDPGO: Efficient Self-Distillation Training Meets Proximal Gradient Optimization”为题,发表于中国计算机学会CCF A类会议NeurIPS 2025上。
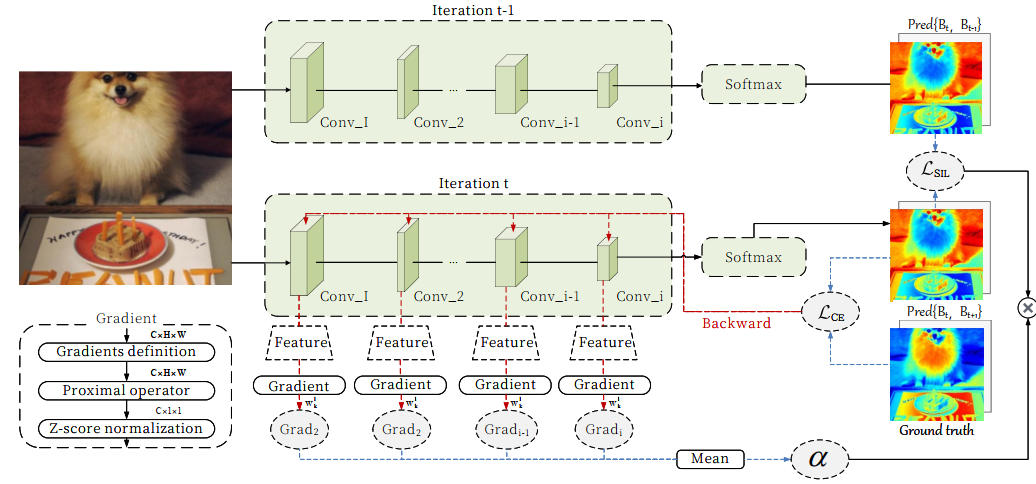
上图为SDPGO框架的整体结构。
在深度学习领域,知识蒸馏(Knowledge Distillation)已被证明是一种有效的模型压缩与性能提升技术。传统方法需要依赖预训练的教师网络指导学生网络训练,而自知识蒸馏(Self-Knowledge Distillation, SKD)则突破了这一限制,仅通过单一模型自身输出实现知识提炼。然而,现有SKD方法大多侧重于普通特征的复制,未能充分挖掘对学习性能提升至关重要的关键特征。针对这一局限性,研究人员提出了创新性解决方案——基于近端梯度优化的自蒸馏训练框架(SDPGO)。该框架通过梯度信息识别并强化对分类性能影响显著的特征,使网络在训练过程中聚焦于最相关的特征表示。首先,研究团队将梯度信息精炼为动态变化的加权因子,通过评估蒸馏知识的重要性,实时调整特征学习权重。该机制使模型能够自动识别并优先学习任务关键特征,显著提升自蒸馏效率。其次,通过整合历史预测与实时梯度信息,该模块实现了知识传递的动态优化。基于小批次的KL散度优化确保了训练稳定性,同时自适应地聚焦于关键特征,形成了高效的自蒸馏循环。与静态自知识蒸馏方法不同,SDPGO能够实时细化知识传递,无需依赖外部教师模型,使模型能够直接从自身的训练轨迹中学习关键特征。该研究优先关注梯度较大的特征,从而引导学生模型聚焦于最具影响力的知识,并适应持续变化的训练动态。
实验结果表明,SDPGO框架在所有数据集上均显著优于当前最先进的知识蒸馏方法,验证了其在不同规模与复杂度的分类任务中的有效性与泛化能力。该研究工作可以在不改变模型规模的情况下提升其性能,从而实现对复杂模型的轻量化处理,可以被有效地部署到资源有限的边缘设备上,从而使智能入户成为可能。
计算机与信息工程学院宿通通博士为第一作者,天津师范大学为第一单位。此项研究获得了国家自然科学基金面上项目(61602345、62002263),国家重点研发计划项目(2019YFB2101900)的支持。
论文链接: https://openreview.net/pdf?id=pbokMgz8e1